{kind=link}
Table of Contents
Introduction
In both science and industry, image processing has played and will continue to play a significant role. It has a wide range of applications, including visual recognition and scene understanding, to mention a few. Most researchers employed imaging approaches that worked well on stiff objects in controlled situations with specialized hardware before Deep Learning. Convolutional neural networks based on deep learning have had a beneficial and considerable impact on the area of picture captioning in recent years, allowing for a lot more versatility. We try to highlight current achievements in image and video captioning in the context of deep learning in this post. Many scholars have contributed to the advancement of deep learning model construction, applications, and interpretation since 2012. Deep learning science and methodology have been around for decades. Still, in recent years, a rising amount of digital data and the use of powerful GPUs have hastened the advancement of deep learning research.
IMAGE AND VIDEO CAPTIONING
Humans face a complex problem when it comes to describing a scene in an image or video clip. Computer scientists have been experimenting with approaches to integrate the science of comprehending human language with the science of automatic extraction and analysis of visual data to construct computers with this capability. Because of the extra complexity of recognizing the items and events in the image and constructing a brief, meaningful statement based on the contents detected, image captioning and video captioning need more effort than image recognition. The development of this procedure opens up enormous possibilities in various real-world applications, including assisting people with varying degrees of vision impairment, self-driving vehicles, sign language translation, human-robot interaction, automatic video subtitling, video surveillance, and more. This article examines the state-of-the-art methodologies for image and video captioning. It does that with a focus on deep learning models.
This article provides a comprehensive overview of deep learning-based image and video captioning approaches, focusing on the algorithmic overlap between the two. Image and Video Captioning are introduced first in this review. The software and hardware platforms that are required to implement relevant models are listed. Finally, there is a Case Study.
A review of both image captioning and video captioning systems based on deep learning is one of the key contributions in this article. The following are some of the contributions:
- The use of image captioning methods as building blocks to construct a video captioning system – i.e., treating image captioning as a repeated subset of video captioning;
- A brief overview of alternative architectures used for image and video captioning;
- Analyze the hardware and software frameworks for developing an image/video captioning architecture; The automatic production of “titles” for video clips is a novel application of video captioning.
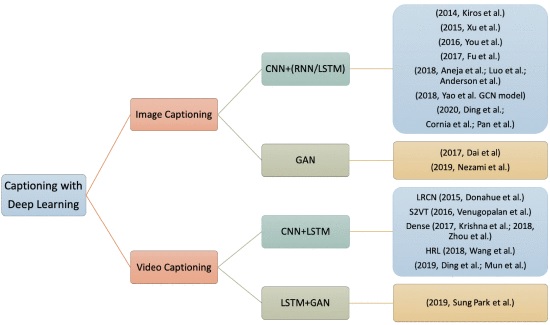
Image captioning has been the subject of numerous notable studies. The process of creating a short description of items and information about the scenes in an image is called image captioning. Image descriptions are frequently created manually. It would be a considerable contribution to automate this process. Many applications can benefit from a system that generates image descriptions automatically. Search engine accuracy, recognition and vision applications, enriching and producing new image datasets, boosting the operation of systems similar to Google Photos, and enhancing the optical system analysis of self-driving vehicles are just a few examples. The technique of obtaining visual information from a photograph and translating them into an appropriate and understandable language are the key issues in image captioning. The traditional retrieval and template-based approaches to captioning began with detecting the Subject, Verb, and Object independently and then joining them using a sentence template. However, the introduction of Deep Learning and enormous advances in Natural Language Processing has had a similar and good impact on captioning.
CAPTION METHODOLOGIES
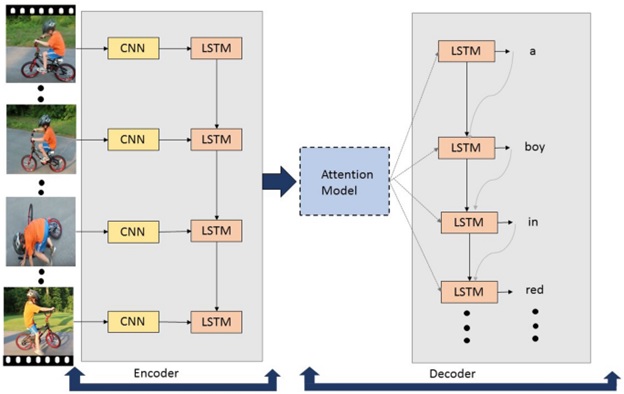
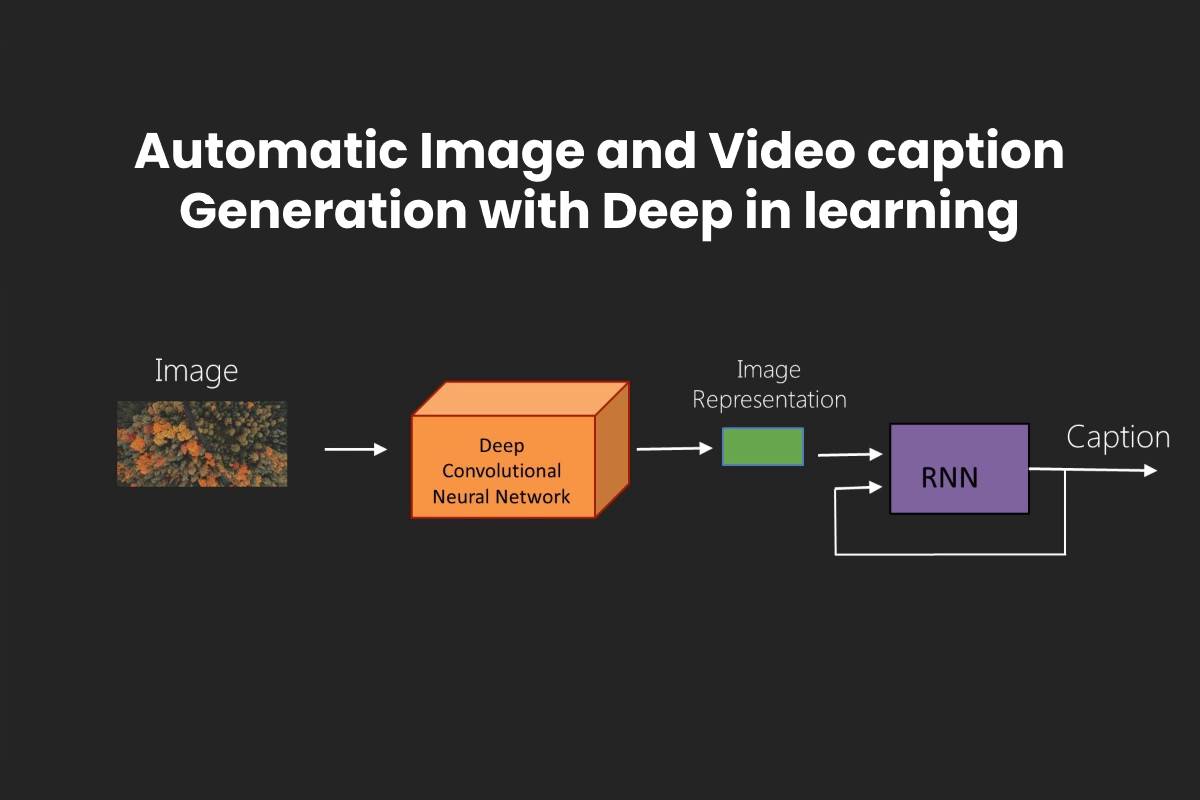
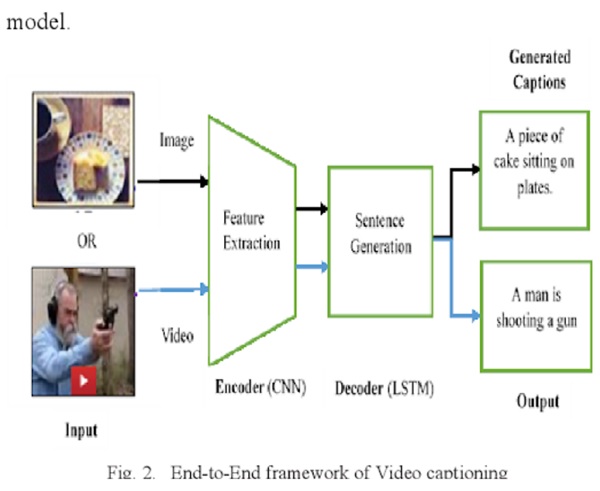
Encoder and Decoder are two components used to automatically generate natural language sentences that describe an image or a video clip. You’ll be able to see the architecture of each part in detail here. The Encoder uses a Convolutional Neural Network. It is used to extract objects and features from an image or video frame. A neural network is required for the Decoder to construct a natural sentence based on the supplied data. Convolutional Neural Network: To learn about thousands of items from a vast number of photos, a model with a significant learning capacity is required. To learn representations of data in images, deep learning presents computational models that are made up of numerous processing layers.
Convolutional Neural Networks based on deep learning are used in a variety of applications, including image identification. Image recognition is used to accomplish a wide range of visual tasks, including comprehending image content. There are several well-known CNN models based on object recognition and segmentation. They are widely used to extract visual information in image captioning and video captioning architecture. Recurrent Neural Networks (RNNs) are a type of neural network that is used. Recurrent neural networks and other sequence models have been widely used in speech recognition, natural language processing, and other fields. Machine translation name entity recognition, DNA sequence analysis, video activity recognition, and sentiment classification are examples of supervised learning issues that can be addressed with sequence models. Cho et al. introduced the gated recurrent unit (GRU) as a gating technique in RNN. The fundamental RNN algorithm encounters a vanishing gradient problem (a challenge in artificial neural network training). The gated recurrent units are an excellent way to deal with the problem of vanishing gradients. They make it possible for neural networks to record many longer-term dependencies. The GRU has the advantage of being a basic model, making it straightforward to design an extensive network with it. It also computes swiftly because it just has two gates. Long Short-Term Memory (LSTM) is a particular RNN structure that has been shown in numerous studies to be robust and powerful for long-range modeling dependencies. LSTM can be used as a component in complicated structures. A memory cell is a complicated unit in Long, Short-Term Memory. Each memory cell is based on a core linear unit with a predetermined self-connection. Because it has three gates, the LSTM is more powerful and effective than a conventional RNN in the past (forget, update, and output). Recurrent neural networks with Long Short-Term Memory can be utilized to construct complicated sequences with long-range structures.
CONCLUSION
We have seen Image Captioning in this article, a multimodal process that entails analyzing an image and explaining it in natural language.
This article should inspire you to find new tasks that can be solved with Deep Learning so that the industry can see more breakthroughs and advances.