{kind=link}
Updated: June 2026 Specifications of models, tool versions, and market data in this guide are updated quarterly. AI models are developing fast with changes in context window, number of parameters and fees checked on each guide update.
Table of Contents
Introduction
Natural Language Processing (NLP) is a branch of artificial intelligence that enables computers to understand, interpret, and generate human language. It powers technologies such as ChatGPT, Siri, Google Translate, sentiment analysis tools, chatbots, and voice assistants.
Really, consider just how linguistically complicated human language is; ‘bank’, for example, can refer to a financial institution or the edge of a river. Sarcasm, slang, dialects and idioms pose a problem even to people, never mind computers. NLP is the engineering field that attempts to do that.
And the stakes have never been higher.
As per the well-referenced industry benchmarks from IBM and other research organizations, ‘humans produce enormous data every day often cited as more than 2.5 quintillion bytes and more than 80% of it is unstructured text and speech’, in the form of emails, social media updates, consumer reviews, medical records, case files, news articles, etc. NLP is the technology that unlocks this data for processing by algorithms. It also powers modern customer communication systems, including AI-driven chatbots, voice assistants, and solutions developed by leading IVR companies that use natural language understanding to improve customer interactions.
: The Complete Guide 1")
With NLP, organizations can:
Know what your customers really mean in reviews and support tickets Automate thousands of hours of manual document processing Instantly translate your content across hundreds of languages Predict health risks from unstructured clinical notes Power human-like intelligent chatbots.
This is your one-stop shop to understanding Natural Language Processing from the ground up whether you are a business executive evaluating NLP investments, a developer setting up your first NLP pipeline or an inquisitive reader trying to piece this world-changing AI revolution together.
Here’s what we’ll cover:
- What NLP is and how it differs from related fields
- The fascinating history of NLP from the 1950s to today
- How NLP actually works under the hood
- The fully developed NLP pipeline, stepwise
- Core technologies like Tokenization, Embeddings, and Transformers
- Large Language Models, Chatbots, and Voice AI
- Sentiment Analysis and other real-world NLP applications
- Most effective methods for applying NLP techniques
- NLP trends over the next decade
First, let‘s go over some basic definitions.
What is NLP?
Natural language Processing (NLP) is part of the wider field of artificial intelligence (AI) dealing with the processing of computer(or artificial) languages in interactions with natural languages.
Natural language” covers all the language we really use, whether it‘s English, Mandarin, Spanish, Malay or one of the many other millions. They differ from “formal languages” programming languages, for example which are rigid, precisely defined, and internally unambiguous.
NLP sits at the intersection of three disciplines:
Discipline What It Contributes to NLP
Computer Science Algorithms, data structures, and computational efficiency of algorithms
Linguistics Grammar rules, syntax, semantics, and phonology
Artificial Intelligence Machine learning, Neural networks, and statistical modeling
How do they compare between NLP, NLU and NLG?
And possibly the most confusing part of the whole field is how NLP relates to its two subfields. To summarize:
NLP, which means Natural Language Processing is the macro field in which are included all the circumstances concerning a machine who processes the spoken or written language of human being.
NLU (Natural Language Understanding) is the branch of NLU concerned with understanding. It‘s the part that would enable a machine to pick up that a sentence is an angry one. When you punch in ‘I‘m really cross with this product’ into a customer service chatbot, NLU is what makes the system realize that you‘re angry not just that you used the word ‘cross’.
NLG (Natural Language Generation) is the output part. It is the technology generates easy-to-read text from structured data. For example, it‘s the NLG that writes the text when your banking application creates a report of your financial situation.
Here‘s an analogy to illustrate this: We‘ll view the enormity of NLP as our digestive system. NLU can be seen as our stomach processing and digesting everything it receives.
Why Does NLP Matter?
The core challenge here is why NLP is strategically important? It is because of one profound challenge that the vast majority of data in the world is unstructured.
Over the past three years, for instance, IDC, Gartner and other research companies have estimated that 80 90% of enterprise data is unstructured, encompassing everything from text documents to images, audio and video files. Existing databases and analytics platforms are focused on structured data, rows and columns and their associated fields. Whatever else you have is non-existent.
NLP completely opens up this vast field of hitherto unavailable data. For the individual organization, this means a competitive advantage:
- Customer insight from thousands of support tickets, without a single human reading every line
- Risk signals identified in regulatory filings before competitors spot them
- Clinical patterns surfaced from doctor’s notes that improve patient outcomes
- Operational efficiencies form using automaton of the classification of documents and data entries
Simply put, NLP can be summarized as; convert lively, breathing human language into a clean, well-structured, easy to query and accessible data asset.
History of NLP
The tale of NLP has no straight path. It is a story of paradigm shifts episodes where the ‘prevailing wisdom’ of the use of language was challenged by a radically better model. It is key to understanding what the systems we build today can do, and what they cannot do.
: The Complete Guide 2")
Era 1: Symbolic NLP — The Age of Rules (1950s–1990s)
NLP was born in the Cold War in the need for automatically translating languages, particularly between English and Russian.
- 1950 — The Turing Test
Alan Turing Publishing his ground breaking paper “Computing Machinery and Intelligence”. Which posed the question “Can machines think?” He introduced the Imitation Game (the Turing Test as it is now called) as a test for machine intelligence; and therefore set the philosophical groundwork for all future NLP research.
- 1954 — The Georgetown-IBM Experiment
In what was widely thought to be the birth of machine translation, Georgetown University linguists working with IBM were to show the first machine to translate more than 60 Russian sentences into English automatically. The demonstration and subsequent press coverage led to enlightened forecasts that machine translation would be solved within three to five years; they were decades premature.
- 1966 — ELIZA
One of the earliest programs to ‘converse’, if that is the correct word, with people was written by American research engineer Joseph Weizenbaum at MIT. Called ELIZA, it was a program that simulated a Rogerian psychotherapist by analysing the sentence the user entered, using pattern matching, and giving a scripted ask-back. ELIZA itself was merely matching the words from input to certain script answers, and yet many responded to it. This “ELIZA effect” demonstrated that people are willing to attribute understanding where there is only lookalike understanding.
- 1980 — John Searle’s Chinese Room
A highly famous example of the Chinese Room was the mind experiment thought up by the philosopher John Searle. This thought experiment remains one of the most well-cited refutations of artificial intelligence to date. The scenario was: Using a detailed rulebook, they match incoming symbols to outgoing symbols — producing responses that appear to a native Chinese speaker as fluent conversation. The person inside understands no Chinese whatsoever.
Searle’s argument: a computer following rules is doing exactly this. It can simulate understanding without possessing any genuine comprehension. This critique targeted the rule-based NLP of the era — and its implications continue to fuel debate about modern AI.
Limitations of the Symbolic Era
The fundamental problem with rule-based NLP was that human language doesn’t follow rules neatly. Hand-coding grammatical rules for even a single language required enormous effort, and the resulting systems were brittle — they failed the moment they encountered an input the rules hadn’t anticipated. Scaling to multiple languages, dialects, or domains was effectively impossible.
Era 2: Statistical NLP — The Data Revolution (1990s–2010s)
The shift from rules to statistics was catalyzed by two forces: the growing availability of digital text data and the practical realization that hand-coded rules simply couldn’t scale.
The Core Insight
What if you didn‘t tell a computer the rules of a language, but instead just gave it millions of examples and asked it to ‘learn the statistical regularities’?
This shift was transformative. Machine learning algorithms — particularly Hidden Markov Models, Naive Bayes classifiers, and Support Vector Machines — allowed NLP systems to learn from data rather than rules.
The Role of Corpora
Large collections of text (called corpora) became the fuel for statistical NLP. Researchers used multilingual datasets like the translated proceedings of the European Parliament and the Canadian Parliament — documents that existed in both English and French — to train early machine translation systems. The statistical relationships between aligned sentences in two languages gave machines a data-driven basis for translation.
Key Achievements of the Statistical Era
- Significantly improved machine translation accuracy over rule-based systems
- First effective spam filters (still statistical NLP at work)
- Early speech recognition systems with practical usability
- Text categorization at scale for news and documents
Limitations of the Statistical Era
Statistical models were better, but they still treated language as a bag of numbers. They had limited ability to capture meaning — the fact that “I saw a man with a telescope” is genuinely ambiguous in ways that probability tables can’t fully resolve. And they didn‘t perform well on unseen data and needed enormous amounts of labeled training data (costly and time-consuming to generate).
Era 3: The Neural Revolution — Deep Learning & Transformers (2010s–Present)
The deep learning era of NLP has begun when researchers first began to use deep neural networks a computer architecture loosely based on human brain to solve language problems.
- 2013 — Word2Vec
The Google researchers published Word2Vec representing words as dense vectors in a high dimensional space. The breakthrough was that these vectors captured semantic relationships. Words with similar meanings clustered together in vector space, enabling the famous analogy: king – man + woman = queen.
This is not a programmed rule — it is a relationship the model discovered by processing large text corpora containing billions of words. For the first time, machines had a mathematical representation of meaning — not just word frequency.
- 2017 — The Transformer Architecture
The publication of “Attention Is All You Need” by Vaswani et al. at Google was arguably the single most important paper in modern AI. It introduced the Transformer architecture, which used a mechanism called self-attention to consider all the words in a sentence at the same time and determine how relevant they all are to each other.
This greatly amplified parallelization in training, and pioneered random exploration in new dimensions of language modeling.
- 2018 — BERT (Bidirectional Encoder Representations from Transformers)
Google replaced the old, single-directional paradigm with a new training model. This new training model, called BERT, had the BERT model read text both forward and backward. This ability allowed the BERT model to have a much deeper understanding of context and meaning of the text that it was “reading.” The BERT model led to great advances in NLP and was used to improve the algorithms behind search engines.
- 2020–Present — The Era of Large Language Models
After the Transformer architecture itself, the next chapter was to train ever larger models. If you look at the recent saga of GPT-3 (175 billion parameters), GPT-4, Google’s Gemini, Meta’s Llama, and Anthropic’s Claude you can see a clear story emerging.
With Large Language Models (LLMs), we can write code, sum up legal documents, tell a poem, or hold a nuanced multi-turn conversation all from one pre-trained model optimized for the relevant task.
NLP Timeline at a Glance
Year Milestone Significance
1950 Turing Test proposed Defined the benchmark for machine intelligence
1954 Georgetown-IBM Experiment First machine translation demonstration
1966 ELIZA First conversational AI program
1980 Chinese Room argument Foundational philosophical challenge to AI understanding
1990s Statistical methods emerge Shift from rules to data-driven NLP
2013 Word2Vec Words represented as meaningful numerical vectors
2017 Transformer architecture Paradigm shift enabling modern LLMs
2018 BERT released Contextual understanding transforms search and NLP tasks
2020 GPT-3 launched LLMs demonstrate generalist language capabilities
2022 ChatGPT launched NLP enters mainstream public consciousness
2024+ Multimodal AI and AI Agents NLP integrates text, image, audio, video, & autonomous action
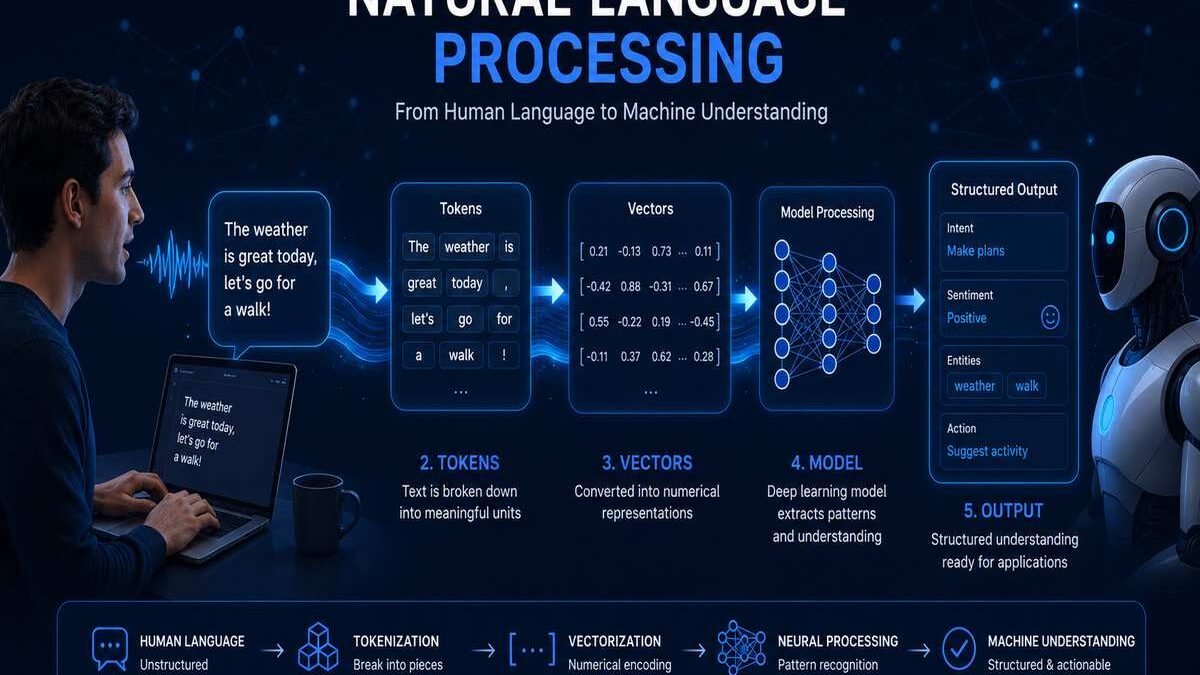
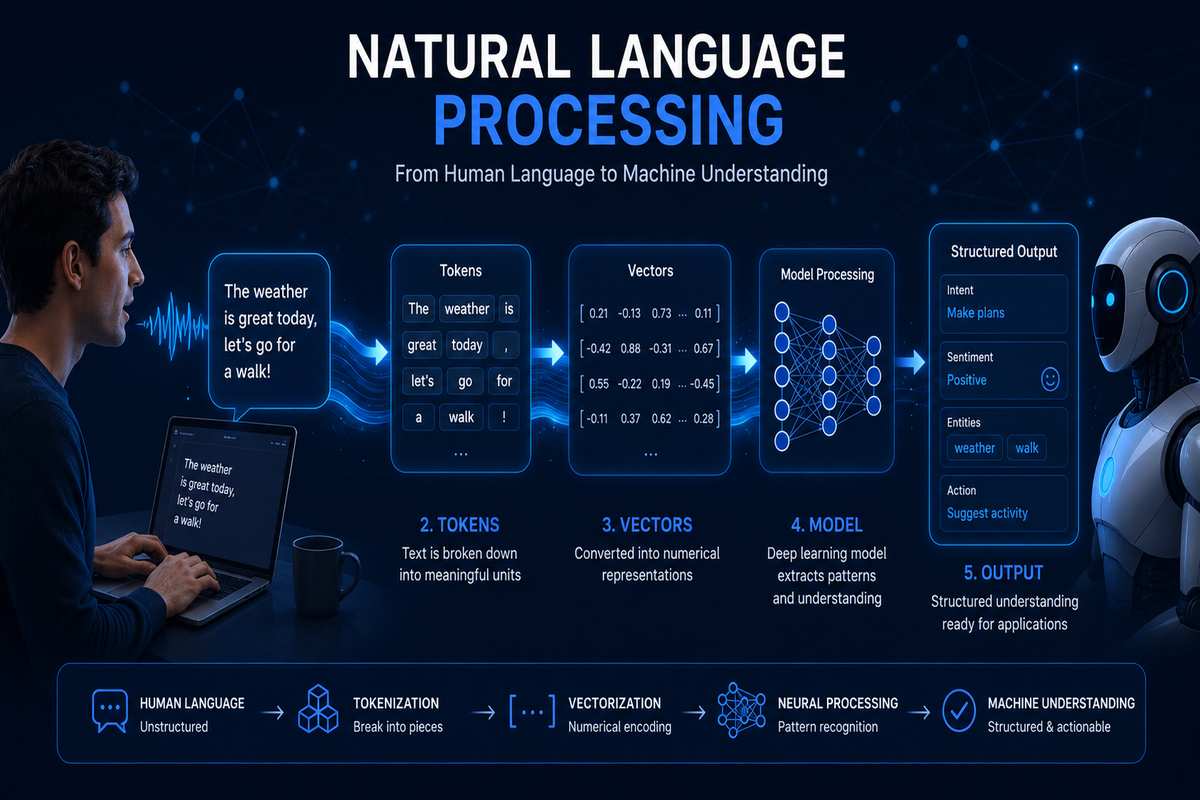
How NLP Works
Fundamentally, NLP takes human language which a computer cannot understand naturally and transforms it into another form that computers can understand: numbers.
It is a complex route from the raw text to a meaningful product output by a machine. I will explain the process into conceptual steps first, and then show you a technical pipeline:
Step 1: Receiving the Input
NLP systems accept input in multiple formats:
- Text — typed queries, journals, emails, facebook and twitter posts
- Speech — voice commands to Phone Call audio recordings.
- Structured text — PDFs, forms, EHR, legal contracts
This first step takes speech as input, and converts it to text before NLP by going through an Automatic Speech Recognition step.
Step 2: Breaking Language Down
All human sentences are hierarchical and non-linear structures. Until a sentence is broken into familiar and manageable units, a machine cannot comprehend it. This involves:
- You can then find individual words and phrases (a process called tokenisation)
- Automatically obtaining the diacritics and POS-tags for each individual word (POS tagging)
- Acquiring the ability to understand the relations between words (parsing)
- Identifying parameters such as names, dates, and locations (NER)
Step 3: Representing Meaning Numerically
If we break language down, we must then convert it into the number level, in the form of vectors (sequences of numbers that encode meaning). The quality of this representation is one of the most critical factors in NLP system performance.
Step 4: Model Processing
A trained model, whether it be a classifier or a big neural network, receives the numbers, and outputs a spam/no-spam classification, a sentiment number, a translated sentence, a reply, anything at all.
Step 5: Post-processing and Output
It‘s formatted for humans. When we talk about NLG, it means to transform the internal representations or structured data into natural language text.
The Key Challenge: Linguistic Ambiguity
It‘s this ambiguity that makes NLP really difficult and that ultimately distinguishes the good systems from the great ones. Human language is virtually shrouded in ambiguity at every level:
- Lexical ambiguity: ‘I walked to the bank.’ (shore of river/ocean or financial institution)
- Syntactic ambiguity: ‘I saw the man with the telescope.’ (who has the telescope?)
- Pragmatic ambiguity: ‘Can you pass the salt?’
Humans therefore easily disambiguate these problems by applying context, real-world knowledge, and pragmatic clues. Teaching computers to do this has been every natural language processor‘s fundamental goal for the past 70 years.
NLP Pipeline
The NLP pipeline is the series of processing steps that raw text has to go through prior to a model be able to process it. Building effective NLP solutions often requires a structured workflow for data collection, preprocessing, model training, and evaluation. Understanding the key steps in developing a custom NLP pipeline can help organizations create more accurate and scalable language-processing systems.
Imagine it a kind of pipeline for language processing, with each step preparing the data to be used in the next.
: The Complete Guide 3")
A poorly conceived pipline can make the difference between a functioning model and a failed one.2 Bad data at any stage compounds, giving a much worse model output in the end.
Here is an complete description of the traditional NLP pipeline (note: more recent systems based on transformers often combine many of these steps into learned representations, but having the whole pipeline is useful for debugging, feature creation, and specialization):
Raw Text Input
↓
<!–citation:1–> Text Cleaning & Normalization
↓
<!–citation:2–> Tokenization
↓
<!–citation:3–> Stop Word Removal
↓
Stemming / Lemmatization
↓
Part-of-Speech Tagging
↓
Named Entity Recognition
↓
Feature Extraction / Embeddings
↓
Model Inference
↓
Structured Output
Stage 1: Text Cleaning and Normalization
Before we linguistically process it, we have to pre-process and clean up the raw text. This involves:
- Removing artifacts from text: HTML markups, URLs, punctuation, special characters, etc.
- Resolving encoding issues: Making certain that character encoding is consistent (generally in UTF-8)
- Normalizing case: Every token is lowercased or applying some other normalization, such as sentence-begin capitalization.
- Contraction processing: “don‘t” into “do not” for easier parsing.
Why its important: A model trained on well normalized text performs way better than one which has to handle and normalize incorrectly formatted text, particularly when working with enterprise data such as emails, PDFs or web-scrapes.
Stage 2: Tokenization
Tokenization is the act of splitting a free text string into a set of tokens. These units are called tokens. They are most commonly words. However, depending on the model, can also be subwords, characters or sentences.
Example:
- Input: “Natural Language Processing is fascinating!”
- Word tokens: [“Natural”, “Language”, “Processing”, “is”, “fascinating”, “!”]
- The majority of recent transformer models use subword tokenization for instance Byte-Pair Encoding (used by the GPT models), where each infrequent word is broken into more likely sub-words:
“unforgettable” → [“un”, “forget”, “table”]
This further cuts down the number of words while using the coverage of in frequent words and technical lexicon.
Stage 3: Stop Word Removal
While not formally defined, many applications require the characterization of so-called stop words, which are highly-frequent words that have little or no semantic information by themselves (such as “the”, “is”, “at”, “which” and “on”). Their removal in principle allows to reduce the input space.
Example:
- Before: “the quick brown fox jumps over the lazy dog”
- After: [“quick”, “brown”, “fox”, “jumps”, “lazy”, “dog”]
Important caveat: Stop word removal is not always appropriate. In sentiment analysis, for example, “not” is technically a stop word, but carries vital meaning (“not happy” versus “happy”). Current contextual models such as BERT tend to skip stop words altogether, as they can balance their importance internally.
Stage 4: Stemming and Lemmatization
Both methods normalize for morphological variants by stemming words to a common root. They differ in approach:
Technique Method Example Output
Stemming Crudely chops word endings “running,” “runs,” “runner” “run” (via rule)
Lemmatization Returns the dictionary base form “better” “good”
Stemming is faster but cruder this can produce non-words (e.g. “studies” = “studi”). Lemmatization is slower but more linguistically correct, as it employs vocabulary and morphological analysis to return the actual dictionary forms.
Why it is important: No normalization means “run,” “running,” “ran,” “runs” are four different words to the model. By stemming/lemmatization all of them will be combined into one word. So there will be a great reduction in the feature space.
Stage 5: Part-of-Speech Tagging
POS tagging: marking each token for its part of speech (e.g. onis a noun or verb or adjective or adverb or prepositions etc).
Example:
The quick brown fox jumps” → [(“The”, DT), (“quick”, JJ), (“brown”, JJ), (“fox”, NN), (“jumps”, VBZ)]
POS tags are very basic features in the way that they are used in parsing, NER and word-sense disambiguation. They tell the system used in a sentence.
Stage 6: Named Entity Recognition (NER)
NER allows to extract and categorize specific entities found in text into defined categories:
Entity Type Examples
Person Barack Obama, Maria Chen, Elon Musk
Organization Google, the United Nations, NHS
Location New York, the Amazon River, Mount Everest
Date/Time January 15, 2025; last Tuesday; Q3 2024
Monetary Value $2.5 billion, €500 million
Product iPhone 16, Tesla Model S
Most of the Information Extraction tasks are based on NER which is the core target for extracting structured information from the unstructured text massively.
Stage 7: Feature Extraction / Embeddings
This is where text is turned into numbers. The method chosen significantly impacts model performance. We explore this in depth in the Embeddings section below.
Tokenization
Tokenization deserves a deeper look because it is the foundational step upon which the entire NLP pipeline rests — and its implementation has evolved significantly alongside model architectures.
Tokenization is the breaking up of raw text into such discrete elements (or tokens) which then become the atomic input for NLP models. As all NLP models need to tokenize input, from simple rule based classifers to the most advanced LLM, all need to be able to perform tokenization.
Word Tokenization
The most intuitive approach — split text at whitespace and punctuation boundaries.
Input: “ChatGPT is revolutionizing NLP.”
Output: [“ChatGPT”, “is”, “revolutionizing”, “NLP”, “.”]
Limitation: Difficulties with compounds, hyphenated words, contractions, and whitespace-less languages (Chinese, Japanese, etc.),
Character Tokenization
Each individual character becomes a token.
Input: “NLP”
Output: [“N”, “L”, “P”]
Limitation: Creates very long sequences, making computation expensive and losing higher-level meaning.
Subword Tokenization
The dominant approach in modern LLMs. Text is split into frequent subword units, balancing vocabulary coverage with sequence length.
Popular algorithms include:
- Byte-Pair Encoding (BPE) — used by GPT models
- WordPiece — used by BERT
- SentencePiece — used by T5 and other multilingual models
Example (BPE):
“unhappiness” → [“un”, “happiness”] or [“un”, “happy”, “ness”]
Finally, the main benefit: we are able to have rare words be a combination of known subwords, thus avoiding the problem of ‘unknown tokens’ so common in the previous models.
Sentence Tokenization
Breaking text into line level units, such as sentences instead of words for applications such as summarization, machine translation, or document understanding.
Vocabulary Size and Tradeoffs
The tokenizer is also responsible for the vocabulary of the model that is, the set of tokens it can be given in order to understand and analyze. The number of tokens in the vocabulary is given in terms of a tradeoff:
- Larger vocabulary → fewer tokens per sentence → shorter sequences → faster processing → but requires more memory and parameters
- Smaller vocabulary → more tokens per sentence → longer sequences → slower processing → but more parameter-efficient
Modern LLMs have vocabularies of about 30,000-100,000 tokens, which balances these conflicting constraints.
Embeddings
If tokenization breaks language into pieces, embeddings are what give those pieces meaning. Embeddings are the bridge between human language and machine computation — the mechanism by which NLP systems represent semantic meaning as mathematics.
An embedding is a dense number vector representation of a word, sentence or document, in a continuous high-dimensional space. The important idea to note is that the geometric location of a token within that space is inherently semantic; similar words are close to each other.
Classic example:
The Word2Vec model famously demonstrated:
vector(“King”) – vector(“Man”) + vector(“Woman”) ≈ vector(“Queen”)
This is not a programmed rule. It is a relationship the model discovered by processing large text corpora.
The Evolution of Text Representations
- One-Hot Encoding (Pre-Embeddings)
Each word is a binary vector, with a 1 at the position matching the word, 0 elsewhere.
Vocabulary: [cat, dog, fish]
“cat” = [1, 0, 0]
“dog” = [0, 1, 0]
Fatal limitation: Each word is the same distance from all the others. There is no way of knowing in this model that “cat” and “dog” are both animals but that “fish” is also an animal, just very different from “pet”.
- Bag-of-Words (BoW)
Bag of Words depicts a document as a vector of its words’ frequencies.
Limitation: ‘The cat chased the dog’ and ‘The dog chased the cat’ are represented in exactly the same way – and they have very different meanings!
- TF-IDF (Term Frequency–Inverse Document Frequency)
Weight words according to their relative importance within a document against a collection of documents. Common words that are used throughout the collection get lower scores.
- Improvements over BoW: Account for importance of words, not just how frequently they occur in a document
- Limitation: Orders and semantic meanings of words are still ignored.
- Word2Vec and GloVe — Static Word Embeddings
Represent each word as a dense real-valued vector (anywhere from 100-300 dimensions).Learn on a large corpus—resulting in word vectors that encode the similarities between words out to the degree permitted by the co-occurrence statistics.
Major flaw: The static embeddings give each word a unique representation no matter the context. The word “bank” has one vector — it cannot distinguish between financial institution and riverbank based on surrounding text.
- Contextual Embeddings — Transformers
The latest models such as BERT and GPT calculate contextual embeddings. A word‘s representation as a vector varies based on context.
- “I deposited money in the bank” → embedding reflects financial meaning
- “We sat by the river bank” → embedding reflects geographical meaning
Same word, different vectors depending on context. The fundamental breakthrough that makes modern NLP possible.
Sentence and Document Embeddings
In addition to word embeddings, current NLP systems also produce sentence, paragraph, and document embeddings, which are important for:
- Semantic search – find documents by meaning (not by keyword) Search the world‘s information, including webpages, images, videos and more.
- Retrieval – Augmented Generation (RAG) time-consuming fetching of relevant context to provide foundation for LLM model answers.
- Clustering – organizing similar documents into groups where no pre-existing categorizations have been supplied.
- Duplicate detection — identifying paraphrases and near duplicates at scale, e.g. at the level of passages.
Specialized models such as OpenAI‘s text-embedding-3-large, Google‘s Universal Sentence Encoder, or Sentence-BERT are designed for efficient production of high-quality sentence-level embeddings.
Transformers
In all of NLP and perhaps even in all of modern AI the most influential development has been the Transformer architecture. Most of the current leading language models that you would currently use ChatGPT, Google‘s Gemini, Anthropic‘s Claude, etc. are all based on the same Transformer framework.
: The Complete Guide 4")
The Problem Transformers Solved
Before the implementation of Transformers, the highest performing architecture for the processing of sequence data, such as text, was the Recurrent Neural Network (RNN) and upon it, the Long Short-Term Memory (LSTM).
RNNs took in text word-by-word from left to right: This created two significant problems:
- The vanishing gradient problem: Data from early in a long sequence became weaker and weaker as it had to go through many sequential ‘layers’. If the model had to write an entire long paragraph it would forget most of what it had said at the beginning.
- Sequential bottleneck: A lot of various words; nothing could go through without the previous word.
Transformers solved both problems simultaneously.
Self-Attention: The Fundamental Mechanism
What is central to the model is self-attention (or scaled dot-product attention). With one operation, it allows us to consider the entire previous sentence at the same time, rather than sequentially by projecting the sequence and outputting a weight between each token.
Example:
Sentence: “The animal didn‘t cross the street because it was too tired.”
What is it named: the animal or the street? Humans immediately understand it refers to the animal. Through self attention, the model can infer “it” has a strong relation to “animal” and weak relation to “street” and represent “it”.
In mathematical terms, for each token position, self-attention computes:
- How much attention to pay to every token in the sequence (including itself), determined by the similarity between its query vector and all key vectors
- A weighted sum of all value vectors, where the weights are these computed attention scores
This happens across all positions simultaneously, enabling parallelization and eliminating the vanishing gradient problem.
Multi-Head Attention
Instead of calculating one attention function, Transformers calculate multiple attention “heads” concurrently each focusing on various features of the text at the same time.
One head could concentrate on syntactic relations (which noun is the subject of which verb), while another might explore semantic relations (which words are thematically related), another on positional relationships, and so forth. The resulting outputs of each head are concatenated together and projected into a final output vector.
The Transformer Architecture
A full Transformer consists of two components:
Encoder
- Processes the input sequence
- Generates rich contextual representations for each token
- Used in models like BERT and RoBERTa (optimized for understanding tasks)
Decoder
- Generates output sequences token by token
- Employs self-attention and cross-attention (attending to encoder output).
- Used in autoregressive generation models like GPT
- Encoder-Decoder (Seq2Seq)
Used for tasks requiring both understanding and generation
Dominant models for machine translation and summarization (e.g. T5, BART)
Why Transformers Changed Everything
Capability RNN/LSTM Transformer
Parallelization ❌ Sequential only ✅ Fully parallel
Long-range dependencies ❌ Degrades with distance ✅ Equal attention across all positions
Training scale ❌ Limited by sequential compute ✅ Scales to billions of parameters
Transfer learning ❌ Difficult to pre-train and fine-tune ✅ Foundation for the pre-train/fine-tune paradigm
The ability to train in parallel meant Transformer models could be scaled to unprecedented sizes by simply adding more compute — leading directly to the Large Language Model era.
Large Language Models
LLMs- Large Language Models make up the state of art area in NLP today. They are gigantic neural networks implementing the Transformer architecture, trained on very large text corpora, and are able to do essentially any language task without any task fine-tuning.
Here the ‘large’ in LLM means mainly the numbers of parameters, the values used in a model (which is learned by training).
Current Frontier Models (mid 2026)
Model Developer Parameters Context Window
GPT-5 series OpenAI Undisclosed 256K+ tokens
Claude Sonnet 4 Anthropic Undisclosed 1,000,000 tokens
Claude 4.6 Opus Anthropic Undisclosed 200K (1M beta)
Gemini 2.5 Pro Google DeepMind Undisclosed 1,000,000 tokens
Llama 4 Scout Meta AI 109B total / 17B active (MoE) 10,000,000 tokens
Llama 4 Maverick Meta AI 400B total / 17B active (MoE) 1,000,000 tokens
DeepSeek-V3.2 DeepSeek 685B total (MoE) 163,840 tokens
Qwen 3 235B Alibaba Cloud 35B total / 22B active (MoE) 128,000 tokens
Note: Many leading AI labs no longer openly publish specific parameter count. Where we list numbers, they come from official developer documentation. “MoE” indicates Mixture-of-Experts architecture, where only a fraction of total parameters are active per inference.
Scale matters because larger models consistently demonstrate better performance across diverse tasks — a phenomenon known as emergent capabilities, where abilities that were absent in smaller models appear suddenly at sufficient scale.
How LLMs Are Trained
LLM training happens in stages:
Stage 1: Pre-training
The model is trained on an immense corpus of text trillions of tokens from the web, books, repositories of code, science papers, other. The training process can be conceptualized as, in the course of each sequence of input tokens, to predict the next-most-likely token. For example, this approach allows it to develop a mature statistical grasp of language, knowledge and reasoning.
Stage 2: Instruction Fine-Tuning
The pre-trained model is further trained on hand-selected datasets of instruction-response pairs to force the model to responds to user instructions better while still doing pure text completion.
Stage 3: Reinforcement Learning from Human Feedback (RLHF)
After human raters compare outputs across models to determine quality, helpfulness, and safety, these preferences are used to train a reward model. The reward model is then used to further optimize the LLM.
What Can LLMs Do?
Recent advances in NLP have been driven by large language models capable of understanding context, generating human-like responses, and supporting voice-enabled experiences. Learn how LLMs and voice cloning power today’s AI companions and reshape digital interactions.
The remarkable property of modern LLMs is their generalist nature. One pre-trained model can be used for:
- Text Generation — creative writing, marketing copy, technical documentation
- Summarization — condensing long documents into concise briefings
- Question Answering — retrieving and synthesizing factual information
- Code Generation — writing, explaining, and debugging code in dozens of languages
- Translation — converting text between 100+ languages
- Reasoning — solving multi-step logic and math problems
- Classification — categorizing text into predefined labels
- Extraction — pulling structured facts from unstructured text
In-Context Learning and Prompt Engineering
One of the most surprising properties of LLMs is in-context learning — the ability to perform new tasks simply by showing examples within the prompt, without any model weight updates.
- Zero-shot prompting: Ask the model to perform a task with no examples
- Few-shot prompting: Provide 2–5 examples of the task within the prompt
- Chain-of-thought prompting: Ask the model to “think step by step,” dramatically improving performance on reasoning tasks
This means that LLMs are remarkably versatile they can acquire a new task in a matter of seconds rather than weeks or months to fine-tune a domain-adapted model.
Retrieval-Augmented Generation (RAG)
One major disadvantage of the large language models (the knowledge is frozen at training time). So, LLMs won‘t provide up-to-date knowledge or any domain-specific knowledge (e.g within the organization) that is not included in the model parameters. Retrieval-Augmented Generation (RAG) gets around this limitation by fusing LLMs with knowledge retrieval models:
- User submits a query
- The system retrieves relevant documents from a knowledge base (using vector similarity search)
- Retrieved documents are injected into the LLM’s context
- The LLM generates a response grounded in the retrieved information
RAG is the architecture powering most enterprise AI deployments today — enabling LLMs to answer questions based on up-to-date proprietary data without the risks of hallucination or stale knowledge.
The Hallucination Problem
In addition, LLMs are well-known to hallucinate, producing natural sounding, confident-sounding language that is factually erroneous. This is not a systematic flaw, but rather, an inherent feature of probabilistic language models: when a model predicts what is the most probable next token, it may thus be most probable for a sentence to be factually false.
Reducing hallucination is a fundamental challenge for deploying LLMs in risky fields, such as healthcare, law, and finance. Existing mitigation techniques involve;
- RAG (grounding responses in retrieved facts)
- Constitutional AI (instruct models to fact check themselves).
- Domain-specific Credible Data Fine-tuned on financial domain specific credible data.
- Output verification pipelines that cross-check claims against authoritative sources
Chatbots
Chatbots are among the most famous and most valuable uses of NLP. From the primitive rule-based bots of the early 2000s to the many AI-based conversational agents of today, bot technology has experienced a huge leap forward.
A ‘chatbot’ is any computer program that attempts to mimic conversation with a human user via text chat, although increasingly voice-based interfaces are used. Chatbots incorporate NLP in the core of their process.
Generation 1: Rule-Based Chatbots
Using decision trees and pattern matching rules given by the programmer; these systems were created. The programmer would be required to pre-define and encode in a script every value the user could present.
Characteristics:
- Fast and predictable
- No learning or adaptation
- Completely fail outside defined rules
Used for simple, structured tasks, for example FAQ bots and menu based IVR systems.
Generation 2: ML-Powered Intent Recognition
With machine learning classifiers these chatbots correctly recognize the type of a user message out of the set of predefined types and extract the entities from the message.
Example:
- User: “Book me a flight to Paris next Friday”
- Intent: BOOK_FLIGHT
- Entities: {destination: “Paris”, date: “next Friday”}
This new generation is Powered by Platforms like: Dialogflow (Google) , Rasa , Amazon Lex etc.
Generation 3: LLM-Powered Conversational AI
The current frontier. Chatbots powered by models like GPT-5 or Claude can:
Participate in open-ended, multi-turn dialogs
Adapting the tone and style of the text accordingly to the user‘s access level is another task. Use variation when writing such as passage length, sentence length, and sentence style, etc. not to sound monotone.
- Handle under specification and ambiguity smoothly
- Produce naturally relevant responses. (Scripted flows)
- Access real-time information via RAG
Key difference: Rather than matching input to a predefined intent, LLM-powered chatbots generate responses dynamically — drawing on vast language knowledge to construct contextually appropriate replies.
The Enterprise Case for Chatbots
The commercial case for enterprise chatbot deployment is compelling:
- 24/7 availability — customer support without time zones or shift constraints
- Infinite scalability — handles simultaneous conversations without degradation
- Consistency — never has a bad day, never gives inconsistent information
- Cost reduction — deflects routine inquiries, freeing human agents for complex cases
- Data generation — every conversation produces structured behavioral data
Practical application: car makers use NLP systems that read the feedback on customer questionnaires or warranty claims, identify quality problems at an early stage based on unstructured text revealing manufacturing problems that only a team of analysts could discover.
Chatbot Design Best Practices
- Establish clear scope understand what the chatbot is capable of and articulate that to users
- Establish elegant fallbacks every chatbot will get out of scope questions, making sure they are gracefully handed off to a live agent is key
- Maintain conversation context — users should never have to repeat information within a session
- Testing for adversarial inputs users will try to break, confuse, and manipulate chatbots; it is critical that we blue-teaming.
- Monitor and iterate performance needs to be continuously monitored and improved through real conversation data.
Conversational AI
It should be noted though, that the term “chatbot” is sometimes used to refer to a particular implementation and Conversational AI as the generic term for all systems able to have a naturally sounding interaction with the user, from this perspective, chatbots, assistants, voice interfaces and AI agents are in the same category.
Why is Conversation AI Different?
Conversational AI offers more than a Q&A process. A most advanced conversational system will be able to:
- Dialogue Management
- Keeping track of the state of a conversation as it unfolds over several turns remembering previous utterances, recognizing references to prior discourse, and shifting topics smoothly.
- Intent and Slot Filling
Identifying the user’s goal (intent) and collecting all necessary information (slots) to fulfill it — often over multiple turns:
- User: “I’d like to book a table”
- Bot: “For how many people?”
- User: “Four”
- Bot: “For which date and time?”
Personality and Tone
Current conversational AI models tend to have a coherent persona for example a particular style of communication, level of formality, and even a brand voice personality.
Multimodal Understanding
Conversations with AI do not have to be restricted to text. Researchers are working on to extend the format to other modalities like voice, images, videos etc. to enable more close-to-human deep level conversations.
Conversational AI in the Enterprise
One of the most common applications of NLP is chatbot technology, which enables businesses to automate customer interactions and provide instant support. If you’re new to this technology, this beginner’s guide to chatbots explains the fundamentals and key benefits.
Customer Service Automation
Top companies utilize conversational AI across all customer service interactions – from common FAQ deflection to multi-turn problem resolution. Large telecommunications providers utilize NLP based conversational systems for intent analysis of customer queries that then feeds cross- and up-selling recommendations of packages, devices and plans.
Organizations are increasingly leveraging NLP-powered conversational systems to streamline communication workflows. For example, using conversational AI to automate inbound and outbound calls can improve customer engagement while reducing operational costs.
Internal Knowledge Management
Enterprise conversational AI lets employees query internal knowledge sources in natural language replacing keyword searches with real, contextual retrieval. Imagine that a financial analyst enters, “What were our Q3 EU revenues relative to last year?” and receives one synthesized response drawing on internal sources all without a single SQL query.
Conversational Commerce
Also, online stores use conversational AI to help consumers choose a product, assemble a complicated order, or give after-purchase guidance as if they were expert employees
The Transition to AI Agents
Perhaps the most significant evolution in conversational AI right now is the move from reactive chatbots, which respond to a specific input, to agentic AI systems that are able to plan, reason, and carry out multi-step actions on their own.
An AI agent doesn‘t just answer questions. Given a goal, it can:
- Break the goal into sub-tasks
- Select and utilize suitable tools (web search, code execution, API calls
- Make decisions based on intermediate results
- Adapt its plan when results are unexpected
- Deliver a final, synthesized output
This is perhaps a fundamental change in the relationship of man and machine from systems that need to be explicitly told what to do at every stage to systems that can seriously be entrusted with the execution of complex goals.
Voice Recognition
Automatic Speech Recognition — sometimes called ASR automatic speech recognition is the conversion of spoken audio to text. It is the enabling input layer for all voice interfaces — virtual assistants, voice search, meeting transcription, and hands free device controls.
How Voice Recognition Works
Step 1: Audio Signal Processing
The raw audio waveform is digitized and processed to extract acoustic features — typically using a representation called a Mel-Frequency Cepstral Coefficient (MFCC) spectrogram, which captures how the sound energy is distributed across different frequencies over time.
Step 2: Acoustic Modeling
Acoustic data is mapped to phonemes. These are the smallest pronounceable unit of sound in a language, such as the /k/ in cat or the /æ/ in cat. The contemporary ASR systems use deep neural networks for this mapping with a common choice being the Transformer architecture.
Step 3: Language Modeling
A language model, on the other hand, predicts the probability of a sequence of words, and selects the transcription that is most likely to be linguistically correct from similar sounding options.
A classic example of ambiguity: The acoustic signals for “recognize speech” and “wreck a nice beach” are so similar.The language model uses contextual probability to select the correct interpretation.
Step 4: Decoding
The system combines acoustic model scores and language model scores to identify the most probable word sequence for the audio input.
Modern ASR Systems
The introduction of the Transformer architecture to speech processing — most notably in OpenAI’s Whisper model — has dramatically improved ASR accuracy across languages, accents, and acoustic conditions.
Key capabilities of modern ASR systems:
- Real-time transcription with sub-second latency
- Speaker diarization, which comprises determining the identity of each speaker the utterance was spoken by
- Multilingual recognition handling code-switching (mixing languages in mid-sentence)
- Robustness to noise performing well under difficult acoustic conditions
- Domain adaption fine-tuning for fieldspecific vocabularies (medical, legal, technical)
- Enterprise Applications of Voice Recognition
Application Description:
- Medical Transcription The physician‘s dictated notes are transcribed and added to the EHR.
- Call Center Analytics Transcribe and evaluate customer calls for training and insight.
- Meeting intelligence Automatic speech to text, summarization and action item extraction from meetings (eg. Otter.ai, Microsoft Copilot)
- Voice Search handling spoken query input for web search and smart speaker applications.
- Accessibility Real-time captioning for deaf and hearing-impaired users Voice-Controlled Interfaces Handsfree device management in manufacturing, healthcare and automotive environments.
Key Challenges in Voice Recognition
- Accent and dialect variation models tend to do very poorly on non native accents and regional accents
- Diarization is challenged by overlapping speech where two users speak at the same time.
- Specialized terminology obscure technical terms are misrecognized frequently Audio quality poor microphones, extraneous noise and compression artifacts make correct answers harder in the audio qaulity task.
Voice Cloning
One of the most impressive (and controversial) uses of current NLP and audio AI is the ability to clone a human voice. For voice cloning, a small sample of someone‘s speech is used to generate a synthetic voice that sounds incredibly similar to the original speaker
How Voice Cloning Works
Modern voice cloning systems use a combination of:
- Speaker Embedding
- A neural network takes as input a reference recording (from just 3 30 seconds of clean speech) and learns to generate a low dimensional embedding of a speaker‘s voice characteristics. (The individual timbre, pitch contours, speaking rate, accent, etc.)
Text-to-Speech Synthesis
A TTS(Text-to Speech) model for target speaker, which takes speaker embedding and text as input, can generate the audio reading the target sentence.
Neural Vocoders
A neural network (vocoder) is then used to produce the audio of high quality and humanlike characteristics from this acoustic representation.
Cloning voices can be done to a very high standard using modern systems such as ElevenLabs, Microsoft VASA and the OpenAI Voice Engine. The voices produced by these systems are virtually indistinguishable to a human listener.
Legitimate Applications of Voice Cloning
Content Creation and Media
- Podcast hosts and YouTubers can generate audio content in their own voice without re-recording
- Audiobook narration at scale, enabling authors to produce professionally narrated content efficiently
- Localization of video content — dubbing videos into new languages while preserving the original speaker’s voice characteristics
Accessibility
- Restoring voice for individuals who have lost the ability to speak due to conditions like ALS
- Preserving the voice of individuals before voice-affecting medical procedures
Entertainment and Gaming
- Extending voice actor performances without additional recording sessions
- Generating dynamic, contextually appropriate character dialogue in video games
Enterprise Communications
- Consistent brand voice across multilingual markets
- Personalized audio notifications and alerts at scale
The Ethical Minefield
Voice cloning is probably the largest ethical challenge in the field of NLP today. The same technology that enables accessibility tools and creative applications also enables:
- Fraud and social engineering — cloning a CEO’s voice to authorize fraudulent wire transfers (a documented attack vector)
- Non-consensual impersonation — creating synthetic audio of real people saying things they never said
- Political disinformation — generating realistic fake audio of political figures
- Erosion of audio evidence — undermining the evidentiary value of recorded speech in legal proceedings
Current Safeguards and Challenges
The industry is developing several mitigation approaches:
- Watermarking — embedding imperceptible signals in synthetic audio to identify AI-generated content
- Consent verification — requiring explicit consent from the voice subject before cloning
- Deepfake detection — AI models trained to identify synthetic audio by detecting statistical artifacts
- Regulatory frameworks — emerging legislation in multiple jurisdictions addressing voice cloning consent and disclosure
What to remember: Voice cloning technology should not be used in any situation where trust, authenticity or identity is important without strong governance controls in place. Those utilizing voice AI must define policies on consent, disclosure and abuse.
Sentiment Analysis
Sentiment analysis(also called opinion mining) is the NLP task of identifying and extracting subjective information in text. In this context, subjective information contains the writer‘s feelings, attitudes and opinions towards an entity. In simple terms, it involves classifying the given piece of text as positive/negative/neutral.
: The Complete Guide 5")
What is Sentiment Analysis?
Sentiment analysis, (also called, opinion mining) is the NLP task of identifying and extracting subjective information in source materials. This primarily includes the sentiment, attitudes and emotions of the author regarding some topic.
Text is sub-classed as positive, negative or neutral. Some more advanced use cases would be:
- Signalling the strength of said sentiment (strongly positive vs. slightly positive).
- Choose the emotion that you are experiencing (happiness, anger, fear, awe, disgust, sadness).
- Doing it at the level of individual aspects. For example, Understanding whether a large number of users have positive or negative opinions about the battery life of a product, or the usability of a website.
- Detecting irony and sarcasm – one of the most difficult tasks in NLP, e.g. (Kreuz, 2014;Davidov et al., 2010).
Types of Sentiment Analysis
Document-Level Sentiment
- Gives one sentiment value for a complete-document or review.
E.g., a movie review is generally categorized as “Positive”.
Sentence-Level Sentiment
- It considers sentence by sentence sentiment, taking into consideration that a document can contain equal sentiment.
Aspect-Based Sentiment Analysis (ABSA)
- The most specific and commercially attractive category. Instead of treating the sentiment in general terms, ABSA Extracts mentions of entities or facets within the expression and ascertains the sentiment on these individually.
Sample review: “Great food but the service was painfully slow and the price was ridiculous.”
Aspect Sentiment
Food Positive
Service Negative
Price Negative
ABSA gives businesses the specific, actionable feedback they need — not just that a customer was unhappy, but exactly what made them unhappy.
How Sentiment Analysis Models Work
Rule-Based Approaches
Lexicon-based approaches utilize content dictionaries of pre-established words labeled with sentiments ( e.g. VADER, Senti WordNet ). Sentences are then scored by summing over the sentiment analysis of each of the constituent words.
- Advantage: quick, transparent, no training data needed
- Limitation: limited understanding of context, negation and sarcasm (“This film is not bad at all”)
Classifiers (Naive Bayes, SVM, logistic regression) trained on a labeled data set of text with sentiment labels by hand.
- Advantages: Learns domain specific information from data.
- Limitation: Dense training data. Domain dependence.
Deep Learning and Transformer Approaches
Pretrained BERT fine tuning BERT models or sentiment specific models (e.g.Twitter-RoBERTa-sentiment) can obtained state of the art result because of contextual embedding.
- Advantages: Has an edge in handling subtleties and nuances, context of whole text, complicated linguistic phenomena such as negation, quotation, and qualified claims.
- Limitation: Expensive to compute (may not be scalable to large dataset).
Business Applications of Sentiment Analysis
Brand Monitoring
Keep an eye on what people are saying about you on social media, news sites and review sites and forums at all times. Spot public relations disasters early, before they erupt.
Customer Experience Optimization
Analyze support tickets, survey responses, and product reviews to identify specific friction points in the customer journey — and prioritize them by frequency and sentiment intensity.
Product Development Intelligence
Extract aspect-level sentiment from product reviews at scale to identify features customers love, features they hate, and gaps they want filled — providing the product team with a continuous, quantitative voice of the customer.
Competitive Intelligence
Apply sentiment analysis to reviews and social mentions of competitors’ products to identify their weaknesses and customer pain points — informing your own positioning and product strategy.
Financial Market Intelligence
Sentiment analysis on earnings call transcripts, analyst reports, SEC filings and financial news is utilized by hedge funds and quantitatively trading shops to uncover market moving indicators in advance of price.
Employee Experience Analytics
Use sentiment analysis on internal survey data, employee portals, and anonymized communication data to detect engagement, signals of burn out, and management effectiveness concerns.
The Sarcasm and Irony Problem
Sarcastic comments are arguably the hardest thing to detect in sentiment analysis. Consider this sentence: “Oh great, another bug in production”, which has a positive syntax yet negative semantics. Human raters can detect it instantly; most models still struggle.
Current research approaches include:
- Multi-modal analysis (combining text with audio tone or visual cues where available)
- Context window expansion (analyzing surrounding sentences for tone signals)
- Below are several fine-tuning data sets specific to sarcasm (e.g. reddit sarcasm corpora)
NLP Tools
The democratization of NLP has been fueled by a vibrant ecosystem of libraries, platforms, and cloud solutions that have opened up the power of advanced language-oriented AI to enterprises of all sizes. The following is a complete list of NLP tools.
Programming Languages
Python
Python remains the native tongue of NLP development. Speed of development (due to the language‘s excellent readability), rich library ecosystem, and vibrant community support has established Python as the language of choice for rapid prototyping and production model training. Almost every major NLP library, framework, or foundation model API offers first-class support for Python.
Predominantly used in academic research and statistical analysis contexts. The tidytext package provides solid NLP functionality for text mining within R’s data science ecosystem.
Java and Scala
Used in enterprise production environments, particularly for high-throughput NLP pipelines where JVM performance characteristics are advantageous. The Stanford NLP library has strong Java support.
Core NLP Libraries
NLTK (Natural Language Toolkit)
The foundational NLP library for Python — primarily an educational and research tool.
- Best for: Learning basics of NLP, academic use, linguistic analysis
- Main features: Tokenisation, POS tagging, parsing, stemming, corpus access
- Limitation: Slower than more modern options so isn‘t really suited to production at scale
The industry-standard NLP library for production Python applications.
- Best for: Production NLP pipelines, enterprise text processing
- Key capabilities: Fast tokenization, NER, dependency parsing, rule-based matching, custom model training
- Standout feature: Blazing-fast inference speed, designed explicitly for production use
Gensim
Specialized for topic modeling and document similarity.
- Great to use for: Topic modeling, searches through documents and training on word-embeddings.
- Key capabilities: LDA (Latent Dirichlet Allocation), Word2Vec, Doc2Vec, FastText
- Notable aspects: Processing large quantities of text for low memory use
Transformers (Hugging Face)
The must-have library for working with pre-trained Transformers.
- Uses: SOTA NLP tasks with an emphasis on pretrained models
- Provide a variety of pre-train models (BERT, GPT, T5, Llama etc.) that can be fine-tuned or used directly for inference.
- Feature to learn: The Hugging face Model Hub A collection of over 1 million pretrained models for virtually any language and NLP task.
Foundation Models and APIs
OpenAI API (GPT-5 series)
The most widely deployed LLM API. Allows developers to embed the power of text generation, summarization, classification and reasoning into applications through a simple REST API.
Anthropic Claude API
Anthropic’s Claude models offer context windows up to 1,000,000 tokens, strong reasoning capabilities, and emphasis on safety and helpfulness.
Google Vertex AI (Gemini)
Google’s enterprise AI platform providing access to Gemini models alongside Google’s extensive cloud infrastructure and MLOps tooling.
Meta Llama
Open-weight models (weights publicly accessible) with Llama 4 versions having total number of parameters [109B 200B 400B 1T] in Mixture-of-Experts setting. Llama 4 is the latest state-of-the-art open-weight LLM thus allowing organizations the ability to self-host powerful language models instead of relying on third-party API access.
DeepSeek
Chinese-ai-lab providing low cost, high-performing open-source models (DeepSeek-V3.2 685B parameters) with robust coding, reasoning and multi-lingual abilities.
Cohere
Enterprise-focused LLM provider with strong RAG, embeddings, and classification capabilities — particularly popular for search and knowledge retrieval applications.
Mistral AI
European LLM provider offering efficient, high-performance models with strong multilingual capabilities and competitive open-source releases.
Frameworks and Orchestration
LangChain
The most widely adopted framework for building LLM-powered applications. LangChain provides abstractions for chaining LLM calls, integrating retrieval systems, managing memory , managing memory, and building agents.
LlamaIndex
Specialized framework for building RAG systems — connecting LLMs to external data sources, documents, and knowledge bases.
Haystack (deepset)
An open-source NLP framework for building production search and question-answering systems with RAG capabilities.
Rasa
Open-source platform for designing your own custom conversational AI assistants. Enables full control of intent recognition, dialogue management and generation of responses independent of proprietary APIs.
Cloud NLP Platforms
Amazon Comprehend (AWS)
Managed NLP service with entity recogn1 or PII, sent1 t analysis, key phrases extraction and topic model 1 g – all accessible via API, with no ML knowledge needed for usage.
Google Cloud Natural Language API
Google’s managed NLP service offering entity analysis, sentiment analysis, syntax analysis, and content classification.
Azure AI Language Services
Microsoft’s managed NLP service including text analytics, conversational language understanding, and document question answering.
Oracle Cloud Infrastructure (OCI) Generative AI
Enterprise AI platform offering integration with versatile LLMs — including Cohere’s Command model and Meta’s open-source Llama series — for fine-tuning across NLP use cases such as writing assistance, summarization, analysis, and chat.
Vector Databases (for RAG and Semantic Search)
As embeddings and RAG architectures become central to NLP applications, vector databases have become critical infrastructure:
Database Key Characteristics
Pinecone Managed cloud vector database; simple API; enterprise-grade scaling
Weaviate Open-source; multi-modal; built-in ML model integration
Chroma Free Open source; light-weight; best for local development and trial, comes with demos right out of the box.
Qdrant Open-source; Rustbased; high performance; powerful filtering options
pgvector PostgreSQL extension; adds vector search to existing databases
Choosing the Right NLP Tool Stack
For teams new to NLP, a practical starting configuration:
- Prototyping: Python + Hugging Face transformers + API OpenAI + Chroma
- Production NLP pipelines: spaCy + Hugging Face + Lang Chain + Pinecone
- Enterprise deployment: Hugging Face Enterprise or Azure/AWS/GCP/OCI managed NLP + Llama Index
- Open-source / self-hosted: Llama 4 + Ollama (for local inference) + Lang Chain + Qdrant
NLP Applications
NLP has transitioned from an esoteric research specialty to a mainstream component of today‘s businesses. Every industry is using NLP to bring insights out of unstructured information that was not possible before; automate high-volume language-based processes; and reinvent intelligent software.
Healthcare
Health care appears on the cusp of the opportunity for NLP to truly transform practice a sector producing vast quantities of unstructured text (clinical notes, research articles, patient reviews, discharge summaries) that can fundamentally alter clinical practice if it can be accessed on a broad scale.
Clinical NLP Applications:
- EHR Information Extraction Automatically extracting structured facts (diagnoses, medications, laboratory values, adverse events) from free-text clinical notes.
- Clinical Decision Support makes available some selected pieces of previous patient data, relevant guidelines, policy directives, and applicable evidence, presented to clinicians at the moment of care.
- Predictive Health Analytics detecting early indicators of disease such as sepsis, risk of re-admission, taking medications incorrectly, etc. from longitudinal patient records (liability).
- Medical Transcription — converting physician dictation into structured EHR entries, saving significant documentation time
- Clinical Trial Matching accurately matching eligible patients to relevant trials through matching a patient‘s profile to the complex criteria for eligibility
Use case Example: Clinical NLP is being used in hospitals worldwide to parse medical records for “hidden” risks to the patient-the authors show how specific cues in doctors’ notes and discharge summaries can yield the symptoms of disaster before it actually happens.
Finance and Banking
In financial services, NLP has become a real-time intelligence layer for risk management, compliance, and market insight.
Financial NLP Applications:
- Earnings Call Analysis NLP models examine the language and tone used by executives on earnings calls, identifying hedging language, variations in confidence, or shifts in strategic priorities that could signal an event that will move the markets.
- Regulatory Document Processing a system for extracting information from financial regulatory filings, Basel III filings, and CFTC compliance paperwork with automatic file opening, classification, and processing
- Algorithmic Trading signals sentiment analysis of financial news, analyst reports, social media for predictive signals for quantitative trading strategies
- Anti-Money Laundering (AML) identification of unusual language formations and connections in command texts and inboxes
- Credit Risk Evaluation complimenting quantitative credit models with NLP analysis of the information provided in loan application narratives and supporting documentation,as well as unstructured loan documents.
Legal
No other industry has to deal with the volume and value that lawyers do, so it is one of the most appropriate fields for NLP automation.
Legal NLP Applications:
- Legal Discovery or eDiscovery auto-sorting millions of documents, at superhuman speed, to find those relevant to pending litigation, slashing the time and cost of legal discovery.
- Contract Analysis opening sections of large contracts, to identify the primary clauses, obligations, deadlines and risk provisions; highlighting non-standard clauses or absence of usual provisions.
- Previous Research a semantic search across case law in order to retrieve relevant case by using legal concepts and ideas rather than matching words with words
- Document Summarization rephrasing a multisyllabic legal document to be an executive readable summary.
- Compliance Monitoring (regulations) the process of tracking and understanding changes in laws in different jurisdictions.
Customer Service
Customer service was one of the earliest and remains one of the largest deployment areas for commercial NLP.
Customer Service NLP Applications:
- Intelligent Virtual Agents Chatbots based on LLMs for handling mundane questions, ordering, monitoring, and managing accounts and bug fixing.
- Agent Assist real-time NLP applications for listening to customer service calls and offering agents the appropriate knowledge, recommended response and escalation alerts.
- Ticket Classification and Routing for automatically sorting and prioritising support tickets. This helps to ensure that this information is correctly prioritized among all of your customers’ support issues.
- Voice of customer (VoC) analytics aggregated analyzed through channels of customer feedback (reviews, surveys, support transcripts) to surface systematic quality/experience issues5.
- Churn Prediction — identifying customers showing early warning signals of dissatisfaction through language analysis of their interactions
Insurance
Insurance is a data-intensive industry with enormous document processing requirements — a natural fit for NLP automation.
Insurance NLP Applications:
- Claims Processing – access to basic medical and release form information from unstructured claims documentation, accident reports and medical records.
- Policy Document Analysis analyzing intricate policy language to receive a description of coverage, exclusions, and obligations. Can include administration of third party liability insurance policies.
- PII Redaction automatically detecting and redacting any personally identifiable information from a document to comply with regulation (GDPR, HIPAA, CCPA)
- Identification of spoken language features associated with specific reports of false information. (irony)
- Underwriting Support providing risk-critical data from unstructured documents so that risk decisions in the underwriting process can be more efficiently supported
Real world example: Insurance tech platforms currently allow carriers to use NER and document understanding models to pull policy numbers, expiration dates, and coverages from broker submissions–all from unstructured data and in under six seconds, something that used to take hours of manual data entry per document.
Retail and E-Commerce
Retail NLP Applications:
- Product Review Mining automated aspect-based sentiment analysis of product reviews to help with product development and merchandising decisions;
- Personalized Recommendations NLP applications that combine business, search, and browsing behavior to personalize the recommendations.
- Search Relevance occurs where Semantics search without depending upon a word-to-word match. This technology delivers relevant results even if the search term is only a close match to the keywords used.
- Catalog Enrichment is an automatic description of products, attribute tagging and product categorization from unstructured supplier data.
- Competitive Price Intelligence — monitoring competitor pricing and promotional language at scale
Education
Education NLP Applications:
- Automated Essay Scoring Natural language processing systems that can assess writing quality, opinion strength, and factual correctness at speed
- Intelligent Tutoring Systems (conversational AI systems designed to teach students complex materials and naturally adapted to suit individuals’ personal ways of gaining knowledge)
- Student Support Chatbots AI Chatbots at the university that answered students questions about admissions, course registration, financial aid and campus services.
- Plagiarism Detection Models of semantic similarity to locate paraphrased plagiarism that simpler text-matching tools are blind to
- Accessibility Tools – live captioning, text simplification and translation for students with a disability or language barrier
Real-world case study: How U.S. colleges used a combination of NLP and LLMs (often through IBM Watson Assistant or other commercially available NLP tools) to support students quickly and affordably at scale by resolving common questions about admissions, financial aid, and courses 24/7- saving administrators time for handling more nuanced or complex student issues.
Media and Content
Media NLP Applications:
- Automated Content GenerationNLP systems that read large numbers of news stories and then generate similar style articles from structured data (financial data, scores, weather reports)
- Content Moderation Automated classification of user generated content for hate speech, misinformation, spam and policy violations.
- Personalized News Feeds Categorization of semantically-rich news content and user interests modeling for personalized display of news on news web sites.
- SEO Optimization NLP driven content evaluation tools providing analysis for topical coverage, keyword density, and semantic relevance
Future of NLP
Natural Language Processing is advancing at a pace that makes prediction genuinely difficult. However, several clear trajectories are emerging that will define the field’s direction over the next five to ten years.
Multimodal AI: Beyond Text
The current edge of research in NLP is looking to combine language with other modalities images, sound, video and structured data. They are also getting more flexible as they learn to use more than one modality of data, such as text, sound, video and images.
What this means in practice:
- A medical AI that analyzes a physician’s dictated notes and the corresponding medical imaging simultaneously, generating a richer diagnostic assessment than either modality alone can support
- A retail AI that understands a customer’s photo of a product they like and responds with natural language recommendations
- A manufacturing quality system that combines visual inspection data with natural language maintenance logs to predict equipment failures
- True multimodal understanding represents the shift from specialized language AI to a more general form of machine intelligence — one that interacts with the world more similarly to how humans do.
AI Agents and Agentic Systems
The next evolutionary step beyond conversational AI is the autonomous AI agent — a system that doesn’t just respond to queries but pursues goals, makes decisions, uses tools, and takes actions in the world.
- Current agentic frameworks (LangGraph, CrewAI, Microsoft AutoGen, OpenAI Agents SDK) are rapidly maturing. In contexts, this translates to AI systems that can:
- Proactively research, prepare and generate reports without human input Carry out complex multi-step purchasing operations such as: request for quotes, approval, communication with suppliers, placing orders.
- Monitor and address business conditions in real time Interact with enterprise applications using natural language to trigger billing, fulfillment, and approval processes
Perhaps the most revolutionary change in the history of computing is a transition in human – computer relationship from reactive NLP tools to proactive AI agents.
Knowledge Graphs and Grounded AI
A significant limitation of current LLMs is their susceptibility to hallucination — generating confident but factually incorrect information. The integration of LLMs with knowledge graphs (structured, curated databases of entities and their relationships) offers a path to grounded, verifiable AI reasoning.
In this architecture:
- The LLM provides linguistic fluency and reasoning capabilities
- The knowledge graph provides factual grounding and logical consistency
- RAG mechanisms connect the two in real-time during inference
This combination is expected to enable reliable AI deployment in high-stakes domains like healthcare diagnostics, legal research, and financial advisory — where factual accuracy is non-negotiable.
Cognitive AI and Explainability
The “black box” problem — the inability to explain why a neural network reached a specific conclusion — remains a major barrier to AI adoption in regulated industries.
The emerging field of Cognitive AI seeks to address this by incorporating insights from cognitive science and linguistics into neural architectures.
Our aim is to develop models that are humanly-interpretable in their reasoning not merely statistically-sound. Such models should communicate their reasoning in natural language, report on the references used, and recognize their own areas of uncertainty.
Such interpretability is extremely relevant when applying to banking (explanation of a credit denial), healthcare (explanation of a diagnostic proposal), and law (implying a legal argument to cited precedence). Approximations that help achieve interpretability are: Reinforcement learning, decision trees, feature engineering.
Efficient and Accessible NLP
The current AI landscape has a significant concentration problem: the most powerful models require enormous computational resources that only a handful of organizations can afford.
Several trends are working to democratize access:
- Model Distillation — creating smaller, faster models that approximate the performance of larger ones (e.g., DistilBERT achieves approximately 97% of BERT’s language understanding performance while being 60% smaller and 60% faster)
- Quantization — reducing the numerical precision of model weights to shrink model size and inference cost without significant performance degradation
- Efficient Fine-Tuning (LoRA, QLoRA) — techniques that allow organizations to customize large models for specific domains with minimal computational cost
- Open-Source Models — Llama 4, Mistral, DeepSeek, Qwen, and their successors are closing the performance gap with closed-source models, enabling self-hosted deployment without API dependency
Multilingual and Low-Resource NLP
Today’s most powerful NLP models are predominantly trained on English text — a significant limitation given that less than 20% of the world’s population speaks English. The future of NLP includes a emphasis on:
- Massively multilingual models that can perform with high quality across hundreds of languages
- Low-resource NLP — developing effective techniques for languages with limited available training data
- Cross-lingual transfer learning — enabling models trained on high-resource languages to transfer knowledge to low-resource languages
Important project: both a humanitarian challenge (“linguistic inclusion” in the AI era) and a business opportunity (“worldwide access to markets in native languages”).
Responsible AI and NLP Governance
As NLP systems grow in strength and frequency of application, ethical and regulatory issues are about to become more pressing.
Key governance trends:
- EU AI Act — comprehensive EU regulation categorizing AI systems by risk level and imposing proportional compliance requirements
- Watermarking mandates — regulatory requirements for synthetic content (including AI-generated text and voice) to be identifiably marked
- Bias auditing — standardized methodologies for detecting and mitigating demographic bias in NLP model outputs
- Model cards and data sheets — standardized documentation practices disclosing model capabilities, limitations, training data, and known failure modes
For organizations deploying NLP at scale, the governance frameworks of value must inherently focus on data privacy, fairness in modeling, oversight of model and output performance, and regulatory compliance – grappling with AI governance as an integral operational function.
The Horizon: Language Processing to Language Partnership
While the long-term trajectory of NLP is clearly toward something deeper than more advanced tools, we can envisage these models will evolve into true thought partners as they become more powerful, more robust, more multimodal and more autonomous.
The NLP systems of the near future may not merely summarize documents or classify sentiment. They may even create hypotheses, experiment, locate vacancies in the literature, and develop insight novel ideas thereby augmenting human mental ability in a manner that we can hardly yet imagine.
What it comes down to could be whether that constitutes the greatest area of human potential to be radically empowered ever or the greatest revolution to be displaced, and whether that thus demands the most delicate social and economic treatment of all.
As NLP technology continues to evolve, innovations in generative AI, speech synthesis, and intelligent assistants are creating new opportunities across industries. Explore how advanced LLMs and voice-cloning technologies are shaping the next generation of AI-powered experiences.
FAQs
Q1: Can you tell me what is NLP by simple words?
A: NLP (natural language processing) is a branch of AI that allows computers to understand, process and create human language, this is the technology behind auto-correct, Siri and translation applications and many others.
Q2: What makes NLP, NLU and NLG different?
A: NLP (Natural Language Processing) is the biggest umbrella field of all tasks that include interacting with human languages through a machine. NLU (Natural Language Understanding), on the other hand, is a sub-field of NLP that is concerned with the understanding of language input by recognizing its content and intent. NLG, another sub-field of NLP, is the generation of language in a human-understandable form.
Q3: Is NLP actually included in the domain of artificial intelligence?
A: Yes. Natural language processing (NLP) is a branch of artificial intelligence (AI) involved in the application of AI to computers for processing of natural language. It uses three areas of research, applied machine learning, deep learning and computational linguistics.
Q4: What are the bells and whistles and where will NLP be used most extensivly?
A: Typical uses for NLP are search engines (e.g. ‘semantic search’), virtual assistants (e.g. Siri, Alexa, Google Assistant), chat bots or customer service automation, machine translation (e.g. Google Translate), spam filtering in email, auto-complete and spell-check, sentiment analysis, document summarisation and AI agents automating complex business processes.
Q5: The language most widely used for NLP is?
A: The most popular programming language among developers for NLP development is Python. It is because of the several Python libraries for NLP (spaCy, NLTK, Hugging Face Transformers, Gensim), the deep learning frameworks at disposal of developer (PyTorch, TensorFlow) and the large Python community.
Q6: Arranged what do you understand by the term of a Large Language Model (LLM)?
A: A Large Language Model is a subset of AI models based on the Transformer architecture that are trained on enormous datasets (most currently, hundreds of billions to trillions of tokens). Models of this sort such as GPT-5,Claude, Gemini etc are able to accomplish a wide variety of language- Unsupervised. Solving 8 algebraic tasks (solving, simplification, induction, translation, reasoning, summarization, code generation) without task-specific training.
Q7: How does chatbot differ from conversational AI?
A: A chatbot is one specific kind of program designed to imitate text or speech conversations. The term “conversational AI” refers to the larger set of systems designed for human-to-computer communication virtual assistants such as Alexa, AI agents, and chatbots. The first thing to note is that all chatbots are conversational AI. However, only part of conversational AI is a chatbot.
Q8: What are the Action Functions of Sentiment Analysis?
A: The task of sentiment analysisis to relate the text to an overall sentiment class: positive, negative or neutral. Business applications include in particular brand monitoring, responding to customer feedback, social-media listening, signals from financial markets, employee experience and new product development.
Q9: What are the most difficult aspects of the NLP?
A: Main difficulties are: dealing with linguistic ambiguity (words and sentences with multiple sense), bias in training data, computational cost of large model training, “black box” (lack of interpretability), AI hallucination (precise but wrong generated information) and high robustness across languages, dialects and domains.
Q10: Where are we headed in terms of the future of NLP?
A: The future of NLP (toward multimodal AI simultaneous processing of text, image, audio, and video not just a text-only system; toward autonomous AI agents capable of executing more complex multi-step tasks, toward improved facts grounding methods through integration with knowledge graphs and retrieval augmented generation (RAG) architectures, toward more efficient, cost effective, scalable and general purpose models for the entire spectrum of organizations worldwide, toward more robust multilingual capabilities; and toward standards and tools for explain ability and governance) seems to be (at least) toward NLP systems becoming true intellectual partners rather than just high-end tools.
Q11: Who is voice recognition? Is that similar concept like the NLP?
A: They are not the same thing they may be related but they are different. they use voice recognition ( Speech recognition or ASR) to turn the spoken language into text. NLP then takes this text and interprets it to find the semantics and intent, before providing a reply. Voice recognition and NLP are the input layer and processing layers respectively, and are implemented together in voice interfaces such as Siri, Alexa and Google Assistant.
Q12: What is voice cloning and is it safe?
A: Voice cloning is the generation of a digital replica of an individual‘s voice using a brief sample of their voice audio to synthesize a text-to-speech voice. If used ethically and with a participant‘s informed consent, disclosure and sufficient security controls, it can have many positive uses for accessibility, content creation and localization. If misused, it can be used for misinformation, impersonation and deception. If a company uses voice AI it will have to decide what voice cloning policies it will have in place.
Q13: In what way can AI, and more specifically NLP, be used for improving business decision making?
A: NLP benefits enterprise decision making by providing a more flexible, easy-to-see view of data analysis. An NLP-equipped analytics platform can offer an interface that lets a businessperson ask questions of the organization’s enterprise database using natural language — freeing them from preprogrammed dashboards and leading to more creativity in data exploration.